


The other week I got the chance to speak to Alex Usher, Canadian higher education wonk par excellence and latterly podcaster.
I was more than a little taken aback by his assertion that the REF is “heavy handed”, and that it produced a result that could have been reached much more simply (and much more cheaply) in other ways.
Good question
But he’s not wrong.
Amid all the REF hysteria earlier this year here at Wonkhe we worked to present the results as simply and as fairly as possible. No “grade points”, no spurious league tables. And we also aimed to put the importance of REF into perspective – even in the very largest and most research intensive providers, no more than 10 per cent of income comes from (QR) funds linked to REF results – in most cases that proportion is far, far, lower. And there is a link between QR funds and other (project) research income – but not as strong a link as you might expect.
Without our sector-wide mania for rankings REF would not be as big a deal as it is – the mythology and managerial misconceptions have a lot to answer for there, and much of the work that REF requires at provider level could be minimised if the whole thing felt less painful.
But even stripping all that back – the fact still remains (as Elizabeth Gadd has frequently noted) that you could just take the FTE returned by each provider and allocate funding proportionally and you would get fundamentally the same results.
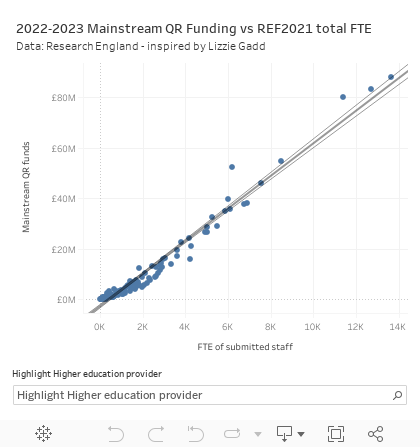
Could we make it easier?
As attractive as it may seem in the abstract, researcher FTE might not be the best way to allocate QR research funding.
It’s an ethically tricky distinction to draw – why are the results of a multi-million pound peer review exercise a valid way to allocate funds, whereas broadly the same result (and allocation) based on a single, cheap, variable is not? FTE is, after all, reproducible – I can get the same data and recreate such an allocation in five minutes. I could spend £24m to re-run the entire REF under the same rules with a comparable set of panels, and the results (based as they are, on academic judgement) could be quite different.
There’s whole research careers to be built on untangling this issue – let me leave it with the idea that even though we see artefacts like this (FTE, is after all, used in allocations – and staff research intensive providers tend to have more time to do research and may thus have time to produce “better outputs”) we do see a value in academic judgement in assessing the work of academics. Even the Office for Students agrees with that.
For that reason today sees the publication of some experimental findings on using data-driven approaches to supplement the REF’s academic endeavour. Academics themselves, of course, have been using data-driven tools to supplement their own work for years now (imagine doing a systematic review without the databases at one level, examine the huge benefits we get from data-mining approaches at another).
A cheaper and simpler REF?
Technopolis and Science-Metrix have been taking a look at making the best use of the data we have to make the reviewer task easier. This is the administrative end of the REF, but also requires a fair amount of insight – categorising and allocating outputs and identifying cross-cutting themes at the start, and testing for bias around output types and interdisciplinary approaches in evaluations.
It’s not a quick fix – using data-driven approaches would require a great deal of prior work in curating the data the algorithm would use, and you do still need the expertise to inform the development of the rules around stuff like categorisation. The report recommends, for instance that using algorithms for allocating outputs to reviewers – and providing a volumetric overview of the “shape” of submissions – is feasible in some of the busier Units of Assessment and as an overview on emerging themes within the whole body of submissions.
It’s very much a case for using computers for what they are good at (pattern matching and recognition, basically) and humans for the higher-order academic judgements. It would also have the side effect of helping us learn more about how the “state of the art” in research is moving.
What about AI?
If you’ve been following the global interest in ChatGPT and suchlike you’ve probably got a slightly overinflated opinion of the state of artificial intelligence. As an old edtech warrior I prefer to think of AI as a fancy algorithm with an attached marketing budget – but there is no denying we are starting to see some impressive looking stuff coming out of this area of research that (start to) live up to (some of) the expectations.
But we are a long, long, way away from using an AI to evaluate academic research reliably. As the University of Wolverhampton’s Statistical Cybernetics and Research Evaluation Group yells in bold type at the very start of today’s research report:
we recommend that AI predictions are not used to help make scoring decisions yet but are further explored through pilot testing in the next REF or REF replacement
In the same way as the result shared above it may be that AI can predict the outcomes in some UoAs pretty well – but not across all subjects and not necessarily for the same reasons (one of the peculiarities of this area of research is you are never exactly sure what the computer is doing or why). Specifically, academic assessments in the medical and hard sciences and economics can be predicted with high accuracy by some kinds of AI – while arts and the traditional social sciences are presented with predictions that have almost no value.
This could be compared with the use of bibliometrics (generally citation-driven metrics, but not Journal Impact Factor because that is never used in REF and should not be something anyone should worry about) – in that it would be additional evidence that could be use to support academic determinations, rather than a replacement. And, interestingly enough – the UoAs that show most promise with this approach are those that already have access to bibliometrics to aid assessment.
The Wolverhampton team have tried a number of approaches to integrating AI assessments with academic assessment – as technology improves, for example, it may be that using AI as an “extra marker” may be feasible. Or, because the AI would also be able to report on likely accuracy of predicting academic assessment grades, using AI only where very high accuracy is likely.
For the next REF and likely the one after “strategy four” looks more likely – allowing sub-panels to choose how to use AI predictions to support decision making. This could in the same way that bibliometrics are used now (as another source of data), to check for consistency between reviewers, or even to replace a third reviewer. However, the report notes that this may not actually save any time, depending how it is implemented.
Nate Silver dot exe
Fundamentally, however, AI is not “assessing” research in any of these scenarios. It is predicting the assessment that would be given by a human assessor.
We work with predictions every day – and we know that more predictions (again, something a computer could iterate very quickly) produce more certainty over accuracy, but we never reach a perfect prediction. Sometimes that one in a hundred outlier is what comes up – an eventuality that humans are far better at spotting and accounting for.
The chance of finding great research where many or all of the usual “indicators” (whatever they may be) are not present has driven a lot of changes in the way research is analysed. We are far more suspicious of bibliometrics now than we ever have been, we take pains to ensure unconscious bias does not mean (for example) researchers from places that have produced great research in the past have themselves produced great research.
Human assessment is far from perfect – but computer-driven assessment is not much better. The combination of the two may well be what drives future improvements, but as today’s releases show there is still a long way to go.










