

“Your work must be your own”. What does that mean?
Jim is an Associate Editor (SUs) at Wonkhe
Tags
I probably took too long to get there (in both contexts) but I was essentially arguing that the concept of “producing” work to be marked looks increasingly meaningless once the availability of feedback is (almost) synchronous during “production”.
It was fascinating because much of the feedback that came tumbling into my inbox consisted of people either assuring me that their detection smarts or tools were reliably catching the cheats, or confessing that those smarts were increasingly being… outsmarted.
Then over this past weekend a cracking new paper from an academic at the University of Hong Kong popped up in my feed.
Jiahui Luo’s call to reconsider the “originality” of students’ work reviews policies on the use of Generative AI in assessment from the 20 top-ranked (QS) universities, and finds that the majority assume a particular underpinning “problem” to be solved – that students may not submit their own “original” work for assessment now that Chat-GPT and its ilk are around:
Terms such as “original work”, “own work” and “authors” are frequently mentioned in the policies. Students are reminded that AI-generated content should not be considered their original work and that they are held accountable for including any such content for assessment. Failure to submit original work, as indicated in most policies, constitutes a severe violation of academic integrity.
Her use of Bacchi’s “What’s the problem represented to be (WPR)” framework, to try to get at the assumptions embedded within rules and policies, is fascinating for the way it contrasts with a search for something that “works” – because that agenda…
…represents a traditional approach to policy analysis, which believes that policies are designed in response to pre-existing problems. The focus of analysis is often on the effects of problem-solving and the problems themselves are left unexamined. Important as it is, this approach views GenAI policies as functional and overlooks how problems can be socially constructed to reflect certain interests and perspectives.
So as well as reminding myself of OfS Condition B4.2 (“Assessments designed in a way that allows students to gain marks for work that is not their own would likely be of concern”), I spent a bit of time yesterday reviewing UK university academic integrity policies to see if I could find similar conclusions.
I’d intended to use some of my forthcoming battles with the rail network to review all of them, but by the time I got to university #30 and its pretty much identical formulation of the issue(s) as the previous 29, I did start to think that the academic integrity working groups that must have produced them all were probably kidding themselves then they all thought they had produced “original” work. hahahaha.
Like the policies in Jiahui Luo’s analysis, all of the universities that I’d plucked at random centre “originality” and “personal authorship” as the main rule to be followed.
As such, both the rules bodged into academic misconduct policies and the sometimes quite convoluted guidance that accompanies them positions AI as a kind of external assistance that differs from individual intellectual efforts.
But at the same time, much of the material that sits on the other end of the see-saw – that sees universities desperate to be seen to be embracing AI – also positions it as a kind of external assistance that differs from individual intellectual efforts.
In other words, AI is sometimes positioned as teacher, offering feedback or frameworks or inspiration – and it’s sometimes positioned as student, doing the actual work for them.
As a result, where AI acts as teacher, it’s all encouraged. Where it acts as student, that’s cheating – because of its role in “production”. That then enables all the existing assumptions about academic misconduct and academic integrity to kick in – it’s about honesty, originality and authorship.
One problem with that is the constant availability of the teacher to provide feedback. If I produce my own work and then give the chatbot the marking scheme and ask for feedback on it, revise it, ask it again and keep going until the bot thinks I’ll get a first, that appears to be fine in most universities’ policies. But it doesn’t feel fine.
And the related problem is, as Jiahui Luo points out by referencing this paper on post-plagiarism, that it’s getting harder and harder to “determine where the human ends and where the artificial intelligence begins” both in the production of work and in the work that goes in before you’re even producing it.
This isn’t all about Elon Musk and having computer chips implanted in your brain (although that’s part of it).
In this fab paper on why generative-AI isn’t a calculator, the authors examine the panic around the extent to which tools provide students with opportunities to just produce the end product, and ramp it up by pointing out that they also appear to offer opportunities to avoid what used to be called learning altogether:
Producing an output completely is a crude descriptor for all the possible uses of generative AI in the process of learning and responding to an assessment task. There are many uses for these tools in the learning process. Cataloguing these uses is, therefore, an important issue and one we will attempt to address in this article through the provision of a typology of uses across two dimensions of machine – human interaction.
You gotta love a simplistic heuristic – and here they contrast different types of tools and their use on two axes. On the vertical AI either undertakes routine “calculator” tasks to alleviate mental workload, or augments human abilities to enhance cognitive capacity. And on the horizontal axis they contrast between an emphasis on the individual student and a much more collaborative thing where humans work with others.
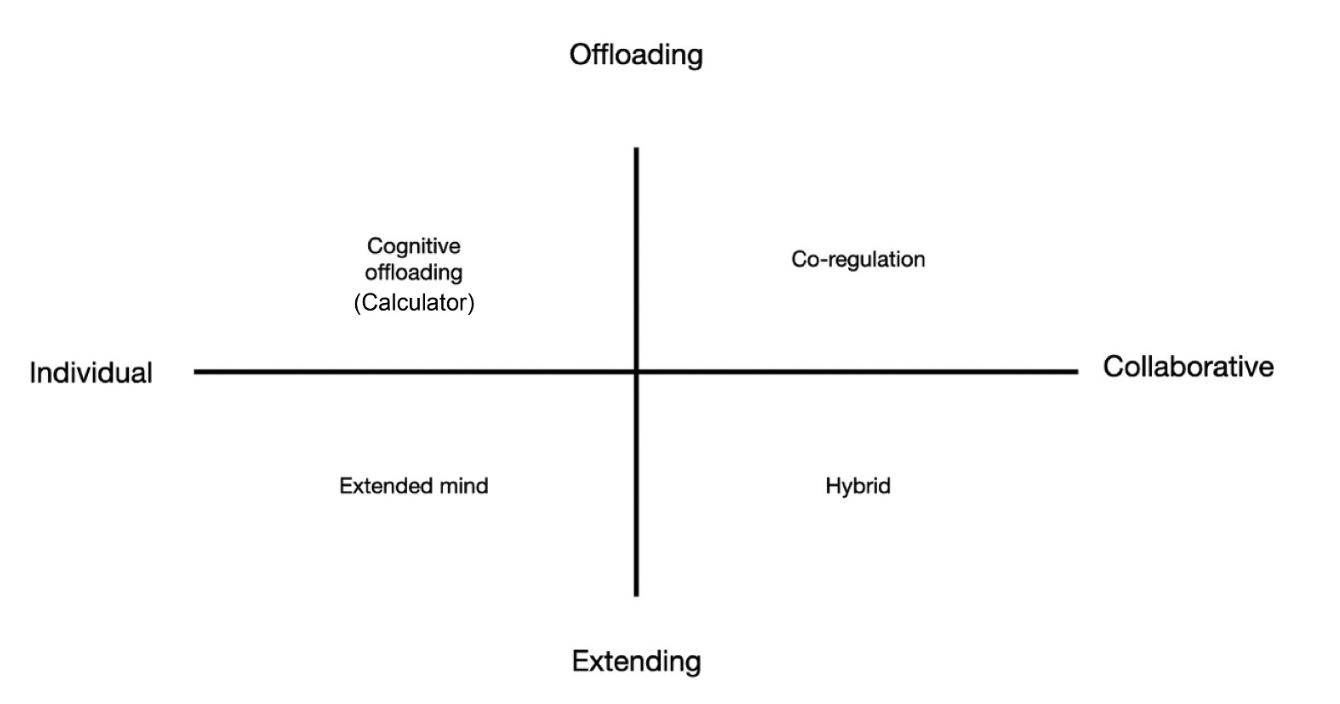
So under “cognitive offloading”, students use tools or tech to reduce the cognitive demand of tasks – which in turn allows them to focus their mental resources (or time) elsewhere, or engage in more complex thinking, or take another shift in the cafe.
We tend to think that’s OK – using a digital calendar to manage deadlines and schedules, using note-taking apps or software to organise and synthesise lecture content and reading materials, using software or calculators for complex calculations so we can focus on concepts rather than computational accuracy, and so on.
Under “extended mind”, the whole idea is that instead of offloading, cognition can extend beyond the brain to include tools and technologies. Again, we tend to think that’s OK – we integrate phones into study routines to access educational resources, we use cloud-based document and spreadsheet software for collaborative project work for real-time cooperation and shared cognitive processing, and students use social media and social space to engage in discussions – expanding their “cognitive environment” to include a bigger community of learners and experts.
For “co-regulator of learning”, the whole idea is that generative AI can collaborate with humans in the learning process by providing support, feedback, and scaffolding (suggest me a structure for my essay, etc), enhancing self-regulated learning. That’s also encouraged – I’ve seen lots of guidance suggesting students use AI to set goals and monitor progress and use tools to provide personalised feedback and recommendations.
Then under hybrid learning, generative AI systems and humans work together on both cognitive and metacognitive bits of learning – like information processing, problem-solving, and content generation (while also helping a bit with the regulation of the learning process).
What’s therefore kind of odd is that AI can be involved in all four – but universities are drawing a weird line through one quadrant and saying that it’s not allowed, while the rest is pretty much celebrated and encouraged. Of course it’s not odd if the purpose of the academic endeavour is “production” rather than “learning”.
If, therefore, a student is using an AI-infused project management app to plan essay milestones, using AI-assisted referencing management software to find and organise sources, using AI tools to interrogate digital archives and databases, using AI-infused mind mapping software to organise thoughts, using AI to summarise discussions in real study groups and using AI to pretend to be in a fake one, using AI to to discuss and refine arguments, and using AI to get feedback on success against marking criteria, style, grammar and standard of English, why would policies only be concerned with the very final bit which may (or may not) churn some text out?
As Jiahui Luo argues, it all results in a pretty pointless definition of “originality” – something that is admitted only once in her review of the “top 20” in this “living document” that is “meant as a conversation” and is “not an official rule or regulation” at ETH Zurich:
Arguably, to a non-vanishing degree, humans are doing the same thing [as AI] when generating what is considered original text: we write based on associations, and our associations while writing come from what we previously heard or read from other humans.
That potentially loops us back around to circular debates about mass HE and unscalable authentic assessment projects – because it’s clearer every day that the production of a “digital asset” as a symbol through which to assess students’ competence and learning doesn’t make any sense.
But it should probably loop us back around to that calculator analogy as well.
That it has been possible since its invention to authentically assess whether students can add, subtract, multiply or divide all on their own doesn’t mean that they’ll ever now need to – just as it was possible to authentically assess my media studies degree skills at physical reel-to-reel tape editing with a knife was possible in 1995, only for it to be clear that only weirdos and nostalgists were ever going to do it from 1996 onwards.
So if – and at least for the next few months, it remains a big if – the whole process of learning, synthesising and communicating knowledge is now not something humans need to be able to do alone, we’re really going need to work out what it is that we do need them to do before we work out how to assess it – authentically or not.
Yet again, great points.
It is becoming apparent that students will use GenAI through all stages of the learning process including preparing for many assessments and generating responses to some. That’s a good thing. It’s exiting.
Some of our assessments, however, must perform the function of checking whether individual students have engaged with the learning material sufficiently and have enough know/understand/can do to be awarded an individual degree. In other words, some assessments will need to be ‘in person’ in one form or another. This challenges those degree programmes that have moved to almost 100% take-away coursework assessments, and maybe that’s no bad thing.
In an AI-infused/led future, society might require different things of us as universities. For the time being, however, we are still in the business of awarding individual degrees to individual students, so all universities need to review their approaches to assessment as a matter of urgency. The world has changed with the advent of GenAI, and we must adapt our assessments too.
The approach you describe seems to be similar to what the University of Sydney are adopting: https://educational-innovation.sydney.edu.au/teaching@sydney/what-to-do-about-assessments-if-we-cant-out-design-or-out-run-ai/
very thought provoking … maybe now what we need to redefine is the word “Assessment” … what it means for the university, the degree and the student. Do we need to move away from how we assess to a more “gurukul” style of continuous assessment ?
These are all very important discussions and there are very compelling arguments to rethink assessment (and not only because of AI).
I would suggest that a capacity for judgement – informed, reasoned judgement within the domain of the chosen subject area – will be a desired quality in graduates whatever happens in this debate. Even if we redefine authorship to encompass ‘collaborative’ uses of AI, wouldn’t we still want and need to discern a student’s capacity to understand and make judgements about what has been produced? (And yes, the traditional essay was rarely a consistently great test of this). Already we can see students who are unable to judge whether the work they are producing with AI-assistance is accurate or not, improved or not, if the AI-feedback is good feedback or not. Why is this? Because they probably haven’t already developed the knowledge or thinking skills that support informed judgement.
Students’ starting points really matter to the design of educational processes. We need to ask things like: When is a university student ready to collaborate with AI (and on what)? What does it take to develop the knowledge and attributes that would support judicious, appropriate use of AI tools? Can AI-as-teacher help with this development? Or (when) might AI stop students from engaging in the (sometimes boring, sometimes difficult) tasks and processes that are associated with development and the acquisition of expertise? Answering these questions requires evidence we don’t have yet. We do have sophisticated, if complex, knowledge about how humans learn. That perhaps is our best guide – our basis for informed judgement – in these challenging conversations.