


There’s a team at the Office for Students that has already started work on the next iteration of TEF.
Unhampered by the continued failure of the English regulator to appoint a “Head of TEF”, this team will attempt to synthesize Shirley Pearce’s superb report with the government’s less thoughtful response. We already know that subject TEF is off the menu, that the ridiculous Teaching Excellence and Student Outcomes Framework (TEF) name/abbreviation pairing will continue. It’s clear that, despite the report’s findings, TEF will continue to be imagined as having a role in applicant choice.
There will be four levels, four aspects of quality, and at least a four year gap between exercises. But there are two instructions to OfS that will play a particularly important role in the development of the new TEF. The first, the blanket acceptance of “most” of Pearce’s proposals, I have covered elsewhere.
The second is this:
we would like the OfS metrics group to take into account and address the concerns raised by the Office for National Statistics (ONS) when reviewing the robustness of its metrics and data.
Brothers in arms
National statistics are not as clear cut as they are often presented. From Covid-19 data, to unemployment reports, to internal migration, to national wellbeing, there is a huge amount of human activity that must happen before, during, and after the collection and presentation of data. We all know that with TEF the devil is very much in the detail, the same is true elsewhere. It’s this synthesis of often scrappy and confused data into a statistic that can be referred to with confidence that the Office for National Statistics excels at – for that reason ONS are the best people to drag TEF into respectability.
The ONS report – “Evaluation of the statistical elements of TEF” – is itself a detailed and thorough undertaking. Though it stops short of asking the central question – whether the metrics and processes that make up the current TEF can fairly be said to describe teaching quality or its absence – the commentary on the mechanics of TEF goes far beyond the procedural. There’s 129 pages of gold here, in other words. I’ve taken a provisional read of it.
Here’s the overall ONS take:
Our main conclusions are that the TEF methods have been developed with a lot of care, and it is commendable that we now have an assessment of a very complicated and difficult-to-measure concept. However, the statistical elements of the current process have the potential to produce inconsistent results, and we think these can be improved. As already noted, there are elements of the communication of TEF, its documentation and guidance on usage, that could be enhanced too.
Alchemy
If you bear in mind that the original purpose of TEF was linked to fee levels, the inconsistencies pointed out here are quite shocking. The ONS makes it clear that the odds of receiving a Gold or Bronze award are far higher for providers with a larger student headcount. The size of a cohort has many impacts on the likelihood that the individual metrics will deviate from the benchmark – and there is no way we can draw a link between this and teaching quality.
Evidence for a number of aspects of our investigation point towards different types of provider being treated differently in some way, and that Gold for a provider of one type currently has a different meaning to Gold for a provider of a different type, though that is not explicitly stated.
ONS gets here via the idea of “flag scores”, and tracking changes in awards from the initial 1a hypothesis to the final announcements – citing some interesting reading on a website called Wonkhe in the process. Larger providers are also more likely to shift between award categories – universities tend to rise and FE colleges tend to sink.
We note that all 14 providers that had their awards downgraded between Step 1a and the end of the TEF Year 3 process were alternative providers or further education colleges; and none of the 22 higher education institutions (HEIs) participating in TEF Year Three had its award downgraded. Meanwhile, 41 per cent of HEIs had their awards upgraded between Step 1a and the end of the process, while this was true for just 6 per cent of the 64 non-HEIs participating in TEF Year Three.
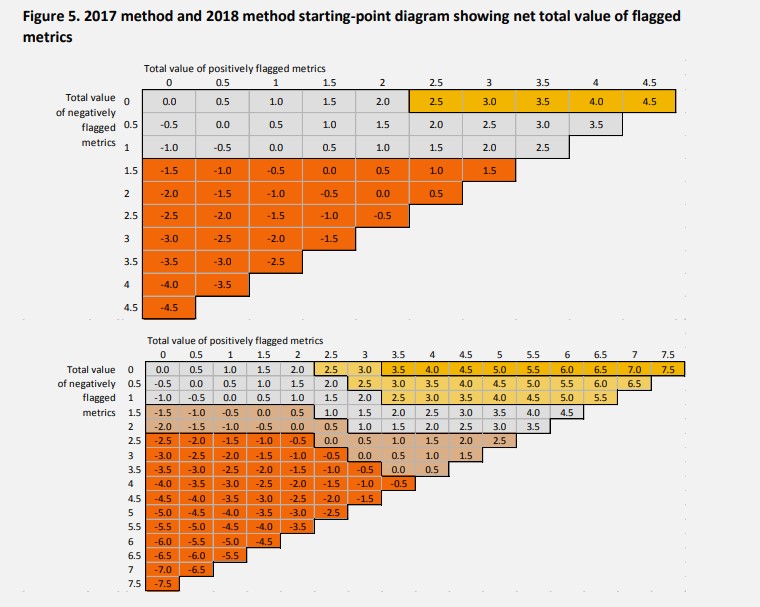
Size is not the only matter of concern – a tiny difference in one single metric between two providers can give one a clear Silver starting assumption (part 1a of the process), while the other is a clear Gold. To be clear, there are two issues that play a role here – the binary nature of the use of statistical significance flags, and the curious (and strangely punitive) design of part 1a. Let’s deal with these issues in turn.
Love over Gold
A flag, from 2017 onwards, is either on or off. Single flags (which indicates in TEF a difference that would not be considered significant in the HESA KPIs that use fundamentally the same data, of course) are given the same weight as double flags (the usual HESA KPI significant test – shown, confusingly, as a single flag in that release). Even given this, positive performance that vastly exceeds the benchmark gets the same credit as performance that is – at best – on the fringes of being confusable with random statistical noise.
This issue is compounded by the painful (but, so so on brand) insistence that any negative flag associated with a provider means it cannot get a Gold award as a starting point under any circumstances. There seems to be an acceptance of how problematic this is, the revised section 1a rules used in the last subject pilot in 2018 allowed a “Gold/Silver boundary” with a single (1.0 weight) negative flag. With masterful understatement, ONS sees it like this:
The TEF documentation seems to regard negative flags as something particularly important to consider, and as something very undesirable.
The main benefit of this approach would appear to be that it would make instinctual sense to a monumentally dim Secretary of State. In practice, a single non-significant drop below a benchmark should not take a provider out of the top category. ONS suggests gradations based on coordinates on a matrix instead of the hard and fast rules – it is right to.
Making movies
But here I am, going on about benchmarking like that is a thing. It would appear that there are serious doubts about the creation and use of benchmarks – both within TEF and more widely. There is a current ongoing OfS internal review of the practice, but the ONS characterises the issue in a particularly clear way:
The concern is that, despite benchmarking trying to ‘level the playing field’ by accounting for the mix of student characteristics present at each provider, there remain other factors that have an influence on the metrics’ reported indicator values that are neither included in the benchmarking factors nor are what TEF is seeking to measure.
The differences between provider performance on each metric may have a link to teaching quality, but will also be linked to other factors divorced from sensible institutional control. For example, highly skilled employment or further study may well be linked to provider teaching quality, but we also know that it has a link to the socio-economic background of students, to the subject of study, and to the region in which graduates live. Benchmarking is an attempt to control for these differences – and gets complicated quickly as you attempt to control for increasing numbers of variables.
Not benchmarking (just using absolute values, as the OfS is proposing in a parallel consultation on quality and standards) means that simply by recruiting students with rich parents to economics courses and then sending them to live in London (OK, not “simply”…) a provider could look like it is performing better than competitors. Which is clearly not a good thing if your goal is to drive up teaching quality.
On every street
The ONS is concerned about assessing all providers together using a common benchmark – noting in particular issues raised when:
• providers of different types contributing to each others’ benchmarks, and thus influencing the TEF outcomes when perhaps that is inappropriate
• the same TEF outcome for providers of different types not necessarily carrying the same meaning, as the outcome awarded would be partly a reflection on some fundamental differences between providers outside what TEF is attempting to measure; the same TEF award category would therefore not be fully comparable between providers.
What it suggests is something that has long been a dream of sector statisticians (and a glorious reality in the Knowledge Exchange Framework) – using comparator groups of similar providers to derive benchmarks. The obvious strength to this is that providers that are not set up to deliver the kind of outcomes you need posh kids and brand recognition for – you can separate out the providers of Veblen goods from those that just teach people useful stuff well. Such an approach would also go some way to addressing the impact of size (why not assess all the smaller providers together?), and region (if graduates stay in the north this is clearly good “levelling up news” even if they may not immediately slot into a corporate graduate recruitment programme.
But one does not, as the meme would have it, simply create benchmarking groups. The process would be riven with assumptions and approximations – and would almost immediately annoy almost everyone, not least the existing mission groups. I’ve long fancied having a go on Wonkhe, but Mark Leach tends to start hyperventilating whenever I mention it.
Communique
TEF is an unwieldy beast. As ONS puts it:
Even after much study of the documentation, we are not convinced we have fully and correctly understood all the criteria and fairly complicated rules.
If ONS – and, franky, if Wonkhe – occasionally struggle to follow the logic that underpins the generation of TEF awards, what hope university managers (who have this as one of 34 urgent things to consider this week) and applicants?
The release of the TEF data by OfS is (rightly) praised, but simply presenting the data in an accessible format is not truly in the spirit of open data. There have been efforts to contextualise and explain the limitations of findings – but this could go further.
For instance, why not disaggregate the individual metrics in external presentation? The data is there if you have the patience or personal inclination to dig through the workbook – but individual aspects of TEF could equally be of use to anyone with an interest in understanding the difference between providers? And, if you are doing that – why not consider ways to show error bars – indicating the certainty of a particular judgement?
Following this argument through, there’s even a suggestion that a “choose your own adventure” TEF, allowing the interested viewer to construct their own weightings based on personal priorities would be of interest to applicants. I’m not sure I’d go that far, but this would also remove the tedious league table aspect of TEF – and maybe stop your vice chancellor spraying gold paint everywhere too.
And do we really need discrete levels for TEF – isn’t everything a fluid continuum these days? Again, this makes it easier to show certainty in a statistical sense, but I fear certainty in a legalistic sense would play better with DfE.
Dire straits
TEF isn’t going anywhere. This may be to the disgust of the commentariat – both from a statistical and an ideological viewpoint – but over and over again the evidence collected and presented by Shirley Pearce show that staff do value the TEF as a driver of institutional interest in teaching quality. The data itself is a useful tool – when appropriately caveated it can shed light on issues of quality that may otherwise never reach the rooms with thick carpets.
If such a thing is to exist, we need to be sure that our TEF is statistically robust, and that the limitations of the design are described (and where possible, controlled for). The politics of TEF is a diverting sideshow, it is the statistics of TEF that will determine the future of the instrument.











Excellent – the not so ‘Solid Rock’ of the TEF
and a nice shout out to Thorstein Veblen
The KEF comparison to TEF is interesting, especially with comparator groups (clusters).
The KEF does use data to drive the clusters, and doesn’t recreate the mission groups exactly (cluster V – ie mostly RG) doesn’t include Durham, Exeter, York or LSE, but does include LBS(!))
But the KEF doesn’t use these clusters for benchmarking, just as a way to group for display purposes. The normalised data is put into deciles for the whole (english) sector.