


The idea that universities should make offers only after the A level results have been announced is not new, and has recently received a major boost by reports from both UCAS and Universities UK, as well as endorsement from the DfE.
Two of the drivers for introducing post-qualification admissions (PQA) are the unreliability of UCAS teacher predictions and the possibility of bias. By conducting the admissions process after the results have been published, any prediction unreliability, and any associated bias, are eliminated.
This is true.
But there is an unstated assumption that the awarded grades are fully reliable.
They are not.
At the Select Committee on 2 September, Ofqual’s Chief Regulator, Dame Glenys Stacey, acknowledged that exam grades are “reliable to one grade either way”. That sounds reassuring, but it implies that a certificate showing grades ABB really means “any set of grades from A*AA to BCC, but we don’t know which”.
That is alarming in general, but especially so as regards PQA, for if grades, as actually awarded, are unreliable, that pulls the rug out from under one of PQA’s main justifications.
What is grade “reliability”?
But what does “reliable to one grade either way” mean?
The answer lies in Ofqual’s November 2018 report, Marking consistency metrics – An update, which presents the results of marking 14 entire GCSE, AS and A level subject cohorts twice – firstly by an “ordinary” (but fully qualified) examiner; secondly by a “senior” examiner, whose mark was deemed “definitive” as was the associated grade.
If grades were fully reliable, 100 per cent of the originally-awarded grades would be confirmed by the re-mark, and no grades would be different. But Ofqual found that this was not the case: for economics, for example, about 74 per cent of the grades were the same, but the remaining 26 per cent were different; the results for other subjects are shown in Figure 1 (taken from Marking consistency metrics – an update)
Figure 1: Ofqual’s measures of grade reliability
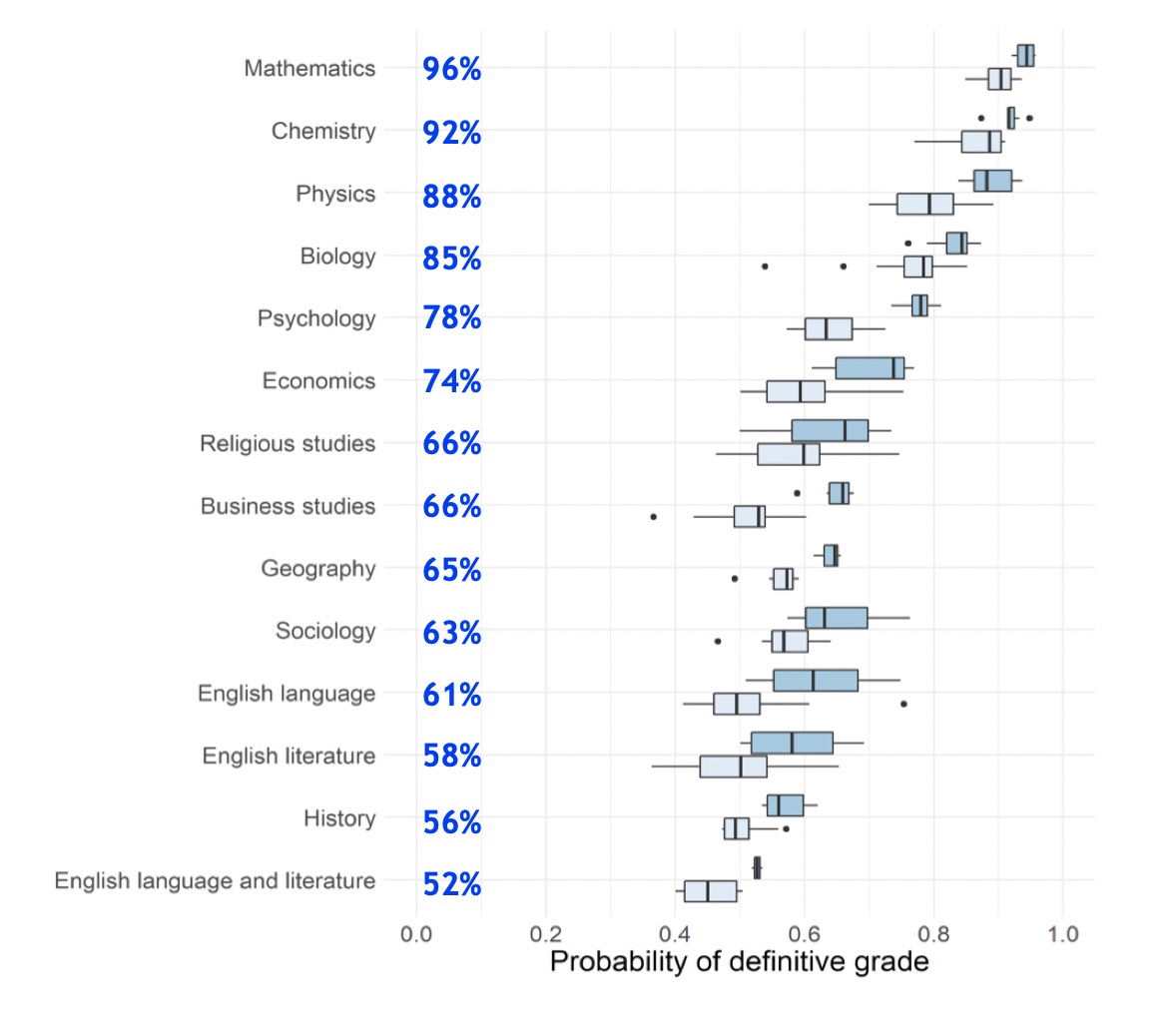
For each subject, the measure of reliability is the heavy line in the darker blue box: as can be seen, Maths grades (all ‘flavours’) are about 96 per cent reliable; Biology, about 85 per cent; Geography, 65 per cent; History, about 56 per cent.
The average reliability of grades across all subjects is around 75 per cent, and this is the basis for Dame Glenys Stacey’s statement that exam grades are “reliable to one grade either way”.
Fuzzy marking
Importantly, the fundamental cause of grade unreliability is not “marking error” or poor quality control of the marking process. Rather, it is the failure of Ofqual’s policies for grading to recognise that all marking is inherently “fuzzy”. As a consequence, the grade associated with any mark whose “fuzziness” straddles a grade boundary will necessarily be unreliable, as shown in Figure 2.
Figure 2: The impact of fuzzy marks on the reliability of grades
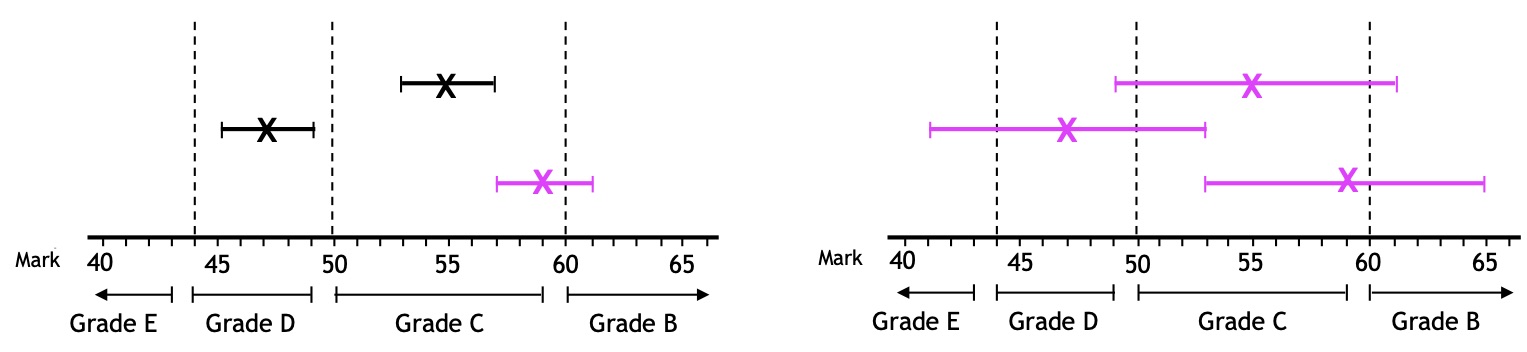
If a script originally marked X is re-marked by a second examiner, there is a possibility that the re-mark will be different. This defines a range of “fuzziness”, as represented by the “whiskers” associated with each mark X. If the range of marks represented by the “fuzziness” straddles a grade boundary, the grade corresponding to the original mark X will be unreliable. On the left is a representation of a less “fuzzy” subject (such as Maths or Physics), for which one of the three grades is unreliable; on the right, for a more “fuzzy” subject (such as Geography or English Language), all three grades are unreliable.
Furthermore – outright marking errors apart – the unreliability of grades is totally explained by fuzziness, and is not related to marking “accuracy” (in my opinion, a problematic word, for it carries an implication that there is a single “right” mark, which there is not), “moderation”, “norm referencing”, “criterion referencing” or any of the other technical terms in the educationalist’s lexicon.
Grade unreliability and PQA
So, back to PQA. Postponing offers until the results are available just switches one form of unreliability (attributable to teachers) for another (that of grades as actually awarded), which is hardly beneficial. What is required is for Ofqual to ensure that the grades, as awarded, are not “reliable to one grade either way” but “reliable, full stop”, meaning that grades as awarded have a very high probability of being confirmed, rather than changed, as the result of a fair re-mark – as indeed is Ofqual’s legal obligation under Section 22 of the Education Act 2011. Surely, reliable grades are a prerequisite of a fair admissions process under all circumstances, whether offers or made before or after the results are announced.
To do this, Ofqual need to change their policy for determining the grade from the script’s mark, and also their policy for appeals. The identification of policies that achieve this is not difficult, nor is their subsequent implementation, so why Ofqual seem to be so reluctant to do this is a puzzle.
Teacher predictions, and how teachers learn
The unreliability of awarded grades also has three important implications as regards teacher predictions.
Firstly, it is certainly the case that the current admissions process incorporates a number of incentives for teachers to be ‘optimistic’ – every teacher wishes to do the best for the students, no teacher wishes to be accused of “ruining my chances”, and there is no sanction for over-prediction. But how is the reliability – or otherwise – of teacher prediction measured?
If this is done by comparing the prediction with the actual outcome, and concluding that all discrepancies are the result of teacher error, then this assumes that the actual award is always right. Since Ofqual’s results were not published until November 2018, any published measures of the reliability of teacher predictions – such as the 2016 UCL-UCU report – must have assumed that the awarded grades are fully reliable. The measures of the unreliability of teacher predictions are therefore likely to be overestimates, for the analysis has not allowed for the possibility that a discrepancy might be attributable to a correct prediction and a wrong grade. This may also apply to more recent studies: UCL’s 2020 report, for example, does not refer to Ofqual’s work.
Negative reinforcement
And there’s a second implication too. Suppose a teacher has four A level History students, and predicts grade B for each. The actual results are A, B, B, C.
“Oh dear,” the teacher thinks. “Two of my four predictions were wrong. I must be pretty hopeless at assessing my students’ performance…”.
But as we have seen, Ofqual’s own data shows that History grades are on average about 56 per cent reliable, so it is to be expected that about half the teacher’s predictions will be ‘wrong’. But the error is the unreliability of the award, not the inadequacy of the teacher. The teacher’s predictions could have been spot-on, but the teacher will never know. And instead of gaining confidence in his or her ability to assess performance, the teacher is thinking “I can’t do this…”.
What is happening is that the errors in grades as awarded are denying the teacher the opportunity to learn: the feedback loop, so fundamental to learning, is transmitting spurious signals, to everyone’s disbenefit.
And there might also be an effect caused by the unreliability of GCSE grades. A student awarded grade 5 at GCSE English Literature might set an expectation in both the student and the teacher of a modest grade at A level. But suppose the GCSE grade should have been grade 7 – an event which is more frequent than you might think, for my simulations indicate that about 1 student in 100 awarded grade 5 actually merits grade 7. So the student’s grade A at A level will be a surprise to everyone.
There surely is an imperative on Ofqual to deliver grades that are not “reliable to one grade either way” but are “reliable, full stop”.









A very good post, reinforcing points made in response to past articles on this site that uncritically presented PQA as a silver bullet.
It is a good read; thank you for this insightful.
Rather than trying to do the impossible and standardize grades much more should be done to standardize assessors through social moderation to calibrate their judgments