


The capability (or otherwise) to detect students’ use of generative AI was the talk of the fringes at Instructurecon, the edtech conference I’ve been at all week.
Down in the exhibition area, a whole host of third party plugin salespeople for Instructure’s Canvas learning management system were attempting to convince wary teachers and learning design professionals that it was their system that could catch students using Chat-GPT and its ilk to protect academic integrity.
The problem was that not only did plenty of the attendees not believe them, even those that did assumed that a high score via one of the tools wouldn’t be enough to prove it and then penalise a student.
The stands canny enough to make clear that their tools might only “start a conversation” were more often than not met with “and what do you suggest the next part of the conversation should be?”
Part of the problem was the much-talked about news less than a month prior that the makers of Chat-GPT had quietly retired their own tool for detection. Back in January at launch, OpenAI was cautioning that the tool was “imperfect.” By mid-June, they’d switched it off altogether due to its “low accuracy.”
What I found fascinating was discovering the way in which many of the tools purporting to be able to detect AI actually work.
Perplexing bursts
Basically, most of the open-source and commercially available tools use two concepts – perplexity and burstiness. Perplexity measures how complex the text is, and burstiness compares variation between sentences. In theory the lower the values for these two factors, the more likely it is that a piece of text was produced by AI.
I wrote a couple of weeks ago about the problems that that generates for non-native writers and the potential for false flagging to disproportionately target students of colour as a result.
In any event, GPT-4 already allows a student to ask the model to be more perplexy (perplex? perplexish? perplexing?) and bursty via the addition of personas, and any number of additional tools can do so too.
I should know – I’ve been experimenting with training a large language model on my own blogs this week, asking it to add in sarcasm, unnecessary exaggeration, spelling mistakes and lots of alliteration.
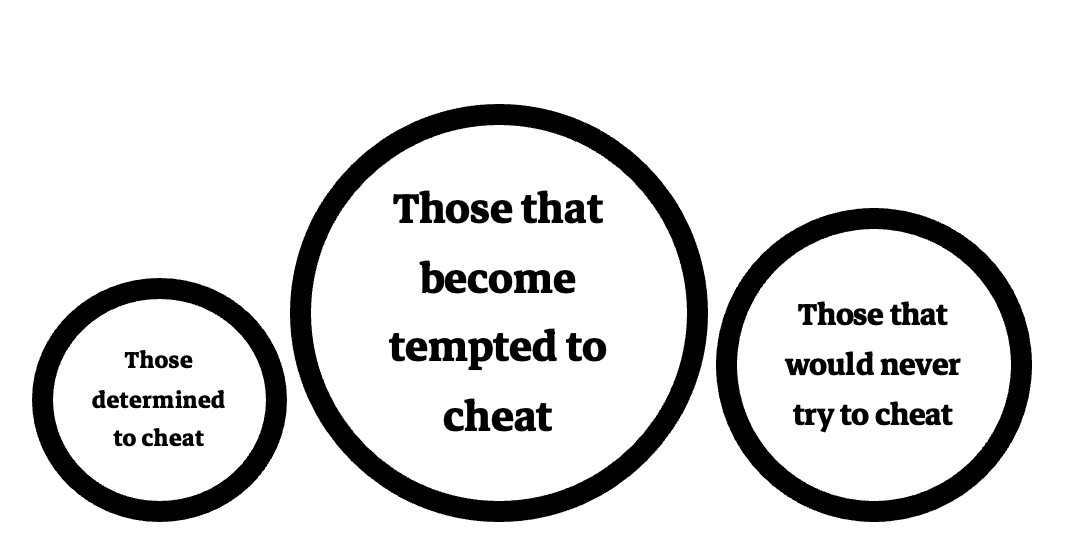
If we imagine students in three groups – those determined never to cheat, those determined always to cheat and those tempted in the middle due to other pressures, the big danger with the approach often on offer is that the use of simple tools “detects” the desperate ones and not the determined ones (and too many of those that would never try).
With all that buzzing around in my head, I’d therefore expected the breakout session from remote proctoring giant Proctorio to provide rich pickings for a suite of tough questions from the difficult Brit at the back as the marketing man attempted to sell the room what was billed as the firm’s…
…comprehensive solution that combines online proctoring, plagiarism, and AI generated content detection.
But to my surprise, what we actually got was the following:
The inherent problem is, what is generative AI? Its whole goal is to mimic human language. So it’s going to be like us and it’s going to use machine learning to do it. I’m hopeful that the market will provide a solution that approaches the problem in a different way. But for right now, that’s where we’re at with this particular technology… AI detection we’re going to leave off.
The rest of the session was a demo of the other suite of online testing tools, where he was evidently more confident about assuring the efficacy of the tools. But if a major anti-cheating firm like Proctorio has already (for now) thrown in the towel to protect its brand, and the inventors of Chat-GPT are also wobbling, it certainly sounds like the arms race may already be over.
The end is near
Earlier in the event Instructure had talked effusively about a partnership it has just struck up with Khan Academy, which has developed a version of Chat-GPT specifically focused on virtual tutoring. In another session there was talk of tools that could find information, develop arguments, and drop them into essays as a study aid.
One of the stallholders in the exhibition area was chatting about how his tool had been trained on all the literature on delivering good teaching, so a busy lecturer trying to develop an engaging hour of learning could get an instant lesson plan.
In this paper in human behaviour journal Nature that appeared this week, psychologists found that AI chatbots have the ability to use analogies just like humans to solve problems.
And as I keep saying to people, the big Microsoft Copilot announcement included the news that any day now, Microsoft Word will have Chat-GPT built right in. A spell checker, a grammar checker and a suggestion of what to write next that’s been trained on what you have in your OneDrive folders makes for a very interesting academic year to come.
One of my nagging feelings was that the tools on offer increasingly give those that buy them the opportunity to do at pace and scale what humans can do – but that their ubiquity means that soon everyone will be able to do the magic tricks.
Higher level learning
But what really struck me as I sat at the back of another session that was wanging on about the calculator analogy again was a conversation I’d had a few months back with someone at a small and specialist arts institution that has moved headlong into graphics design.
Reflecting on my challenge surrounding image-generator Midjourney, he said:
The world will still need artists, Jim.
And that is no doubt true. But how many? If with a single text prompt I can create what it used to take entire teams of game designers to do over many months, the market for what is, for the time being, a buoyant source of graduate ambitions and jobs will simply collapse.
The idea that some of what we learn in education is not necessary for the real world given the invention of machines is as old as those machines – and we’re all used to hearing about the wider benefits of being able to write a sentence, carry out long division or construct an argument.
But the point about most of those arguments is that they surround pretty foundational and almost always compulsory forms of education. Once a student can choose what to study, who would they be studying and then be expected to demonstrate something that the computers can do now too instead?
We might believe there are cognitive benefits to being able to write without prompts in the same way that it might be useful now and again to carry out long multiplication on paper. But once the tools get better than a sole human (with some light moderation) at judging “good” writing, why on earth would it be necessary for all graduates in a mass system to be able to do it?
We might also argue that the development of new styles of writing has to come from somewhere, and that large language models will eventually eat themselves if their training model becomes dominated itself by AI generated text.
But these don’t feel like problems that are likely to be solved by asking students to crack out a pencil and learn Harvard referencing.
What does studying a subject mean?
If “higher level learning” is about concept formation, concept connection, getting the big picture, visualisation, problem solving, questioning, idea generation, analytical (critical) thinking, analogical thinking, practical thinking/application and synthesising/creative thinking, we really do need to accept that in any given academic year, not only can some of these tools now do a lot of that for us, they can already make it look like a student can do those things too if the fundamentals of “studying a subject” remain unchanged.
What is clear is that as the tools become ubiquitous, and GPT-5 rolls into use, the pointlessness of current assumptions about what a graduate is or can do will be seriously exposed. And an associated failure to reimagine the curriculum – around the creation and application of knowledge, and the skills and competencies required to be a better person and foster better conditions for others – could leave universities in the UK in particular looking rather pointless.
That’s why in many ways, I don’t think the big debate about generative AI is really about cheating or assessment at all. It’s much more about accepting that the umbilical link between “teaching” and “research” as we understand it has already been severed. What we think higher-level learning ought to mean – once the activities that universities currently offer to symbolise it become as obsolete as paper-based long division – is the urgent question.









Thoughtful piece. I am wondering when AI detection firms will eventually seek to develop ‘individualized detection’, whereby the detector is trained on an individual students previous inputs, to ‘learn’ that student’s approach to language and structure. From this primary analysis, acting as its baseline, a student submission may be assessed for “AI irregularities”. The problem currently is that there is no individualization of the detection process, hence the often dire prediction consequences met with in reality.
Exactly this! I’ve been saying to anyone who’ll listen at various conferences, somewhere someone is surely developing this already? Accounting for a student’s improvement over the course of a programme (and therefore how this trajectory may be reflected in their written work over that time), feed their text in over time and the learning should detect deviation from individual pattern, syntax, length, lexicon etc…
But there’s nothing to stop the student from putting their previous paper in the tool of their choice and asking it to write in a similar style. To me, one of the answers if for students to see the value in doing it themselves as an exercise to explore their learning. If we can’t convince them it’s worth it, that’s on us. If they choose to use GAI anyway, that’s up to them and, if assessments are meaningful, just means they are cheating themselves.
One of the problems with training LLMs on individual student work is that you would require enough previous written student work. Is there enough (if at all, considering first and in some cases second year students) of that work available? And what if a student trains an LLM themselves on their work before asking it to generate an output?
It’s as Jim says – the arms race seems over. Rather, it is time to re-consider teaching, learning, and assessments in conjunction with this new disruptive technology.
I wonder about the extent to which LLMs are capable of creativity, though. Thinking about your small specialist contact’s point – an LLM learns from what’s available. It’s analogous, surely, to the average of the average (of the average, of the average recursively as time goes on). Its output will cluster around the most common types of expression, whether artistically or in code or in writing. Which still leaves plenty of space for innovation, creativity and imagination to be human outputs. So then higher level learning becomes a question of analysis, synthesis and then the application of those efforts into creativity and creation. Less conformity – let the machines take that – and more innovation and development.