


Now is probably a good time to get your head around the Office for Students’ Association Between Characteristics (ABCs) data.
In a nutshell, OfS uses historic data to build models of access to and continuing in higher education using English 18 year old characteristics and student characteristics. These are predictive (though based on historic data) and offer intersections (allowing you to view the impact of multiple characteristics simultaneously).
ABCs can be understood as a way of exploring these models – which are used to underpin everything from TEF benchmarking to B3 analysis. The data release left experimental status in 2021.
You went to school to learn
There are currently three of these – with the threat of more – covering access to higher education for 18-19 year olds, continuation for full time students and continuation for part time students.
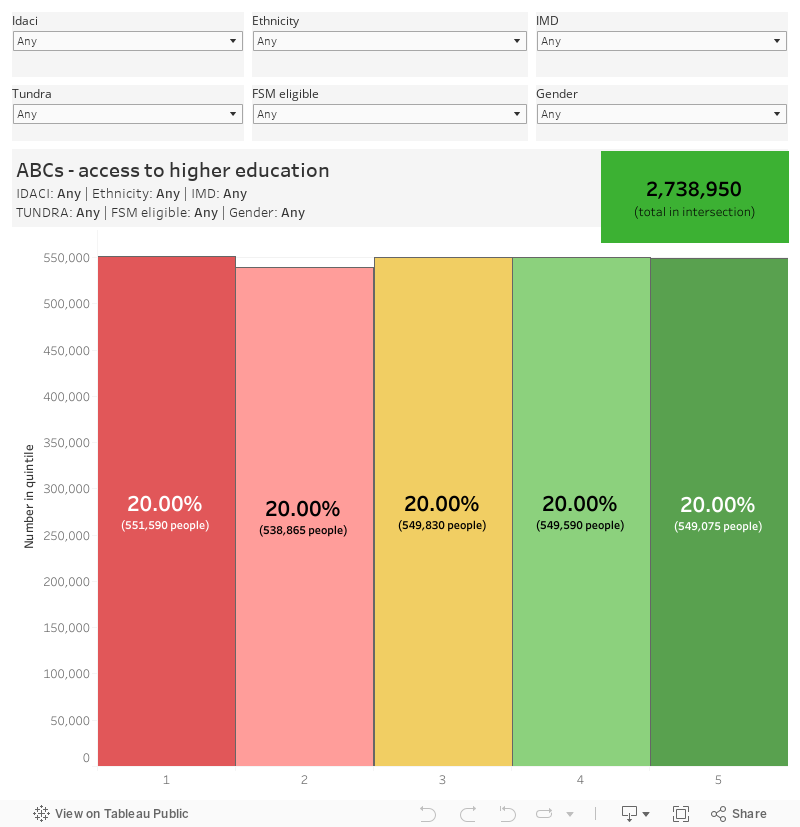
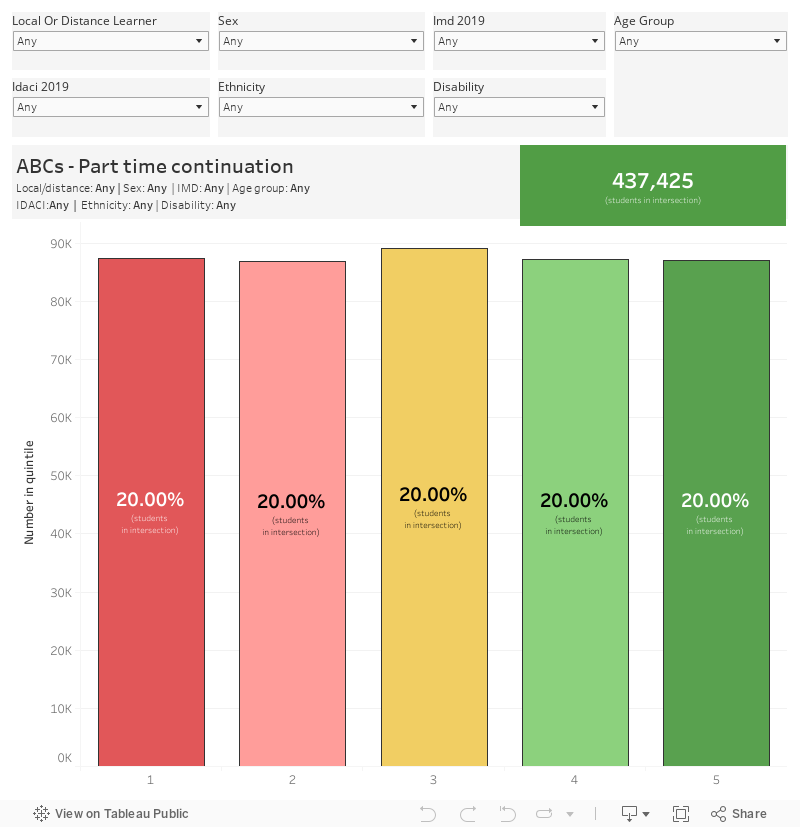
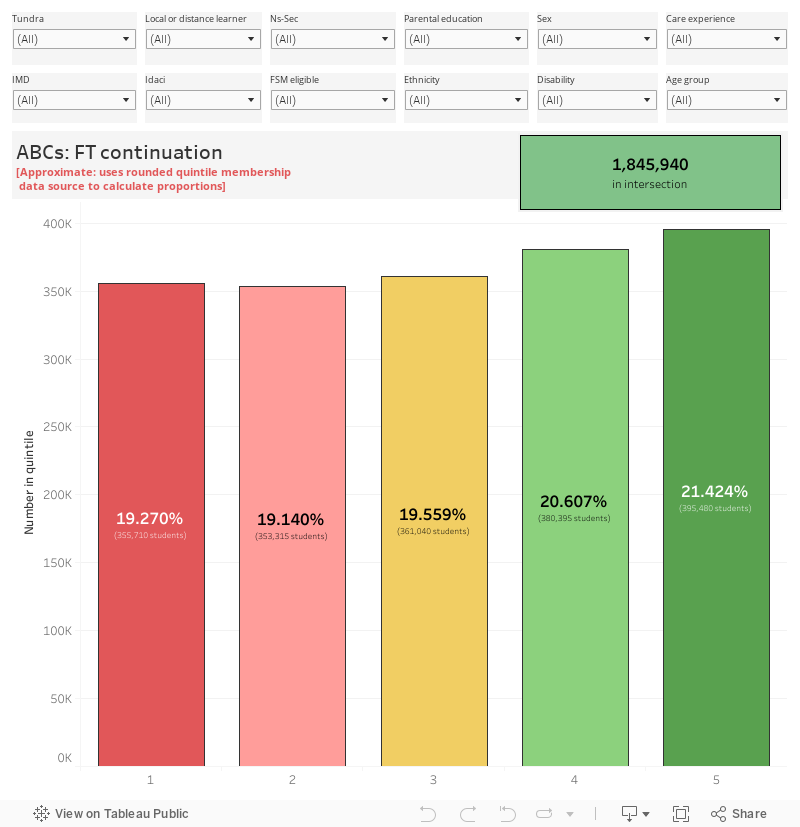
The outputs are presented in quintiles, in the same way as we are used to seeing for stuff like POLAR and TUNDRA. By default the dashboard tells you the proportion of the population in each quintile. For access – where quintile 1 are less likely to access HE and quintile 5 are most likely – we see a mean access rate of 17 per cent for quintile 1 and 66.3 per cent for quintile 5. For full-time continuation – where quintile 1 are less likely to continue into year 2, and quintile 5 are most likely – we see a mean continuation rate of 80.1 per cent for quintile 1 and 95.5 per cent for quintile 5. For part-time continuation, the numbers are 51.6 for quintile 1 and 80.1 for quintile 5.
Each OfS visualisation examines a different population -the total English state school population (for access) or the English domiciled undergraduate student population (for continuation). What the visualisations don’t show you – despite the data being available in the hefty csv downloads – is the number of students under analysis in each case.
Sit yourself down, take a seat
The key differences for access and part-time continuation are that I’ve emphasised the number of students involved in each view – showing the total number of potential applicants/part time students in a box on the top right. The more red that box gets, the more likely we are to see statistical noise creeping in. The bars themselves also show the actual number of students in each quintile.
Access
Part-time continuation
Full time continuation
For full-time continuation the number of rows of data included in the main data release is such that it breaks Tableau Public – something that I’ve not managed to do in the five years I’ve spent plotting everything you could possibly imagine. I’ve put together an approximation using the “quintile membership” data and calculating proportions – because I’m starting with rounded data and omitting some very small “other/unknown” populations you should take this version as being indicative only.
Simple as do, re, mi
The continuation ABCS, in particular, offers us a number of measures we don’t usually see in student data. Notable, and new to me, are:
- NS-SEC: this is the socio-economic background of students based on the highest earning parent/guardian for students who started studies under the age of 21. For students over 21, it is the prior employment of the student.
- IDACI: this is the Income Deprivation Affecting Children Index – assigned to the small (LSOA) area a student comes from, it is the proportion of children under the age of 16 in a low income household in that area.
We also see TUNDRA (which is the state-funded mainstream school remix of POLAR), IMD (the English 2019 variant of the Index of Multiple Deprivation), and data on local students (defined as those domiciled and studying in the same Travel To Work Area (TTWA)).
Branches of the learning tree
Let’s build a hypothesis here – sometimes people don’t continue at university for reasons that could happen to anyone. Maybe they just decided they chose the wrong course, or the wrong place to study. Maybe a family emergency meant plans had to change. And let’s imagine that these things happen, completely randomly, to, say, two per cent of students each year. For a large group of students – say 100,000 – that’s 2,000 students. For a small group of 1,000 students, that’s 20 students.
Now let’s say we know 100 students will fail to continue from the big sample for reason A (which is unique to that sample), and 100 students will fail to continue from the small sample for reason B (which is unique to that sample). On one level, reason A and reason B are equivalent – both affect 100 students. But the non-continuation rate from the big sample is now 2.001 per cent, and the non- continuation rate for the small sample is 12 per cent – cue concerns about a “reason B student retention crisis” in the small sample, while nobody is interested in reason A.
The undertow of the design of data like this is the idea that providers (and indeed the system) have limited resources to support students, so we need to focus them where they will have the most benefit. In this admittedly dismal calculus we should either address issues faced by a large number of the plurality of students, or those faced disproportionately by underrepresented groups.
Anyone who has done any serious student support will know, of course, that the best interventions are those that positively impact the experience of the plurality of students or potential applicants. A regulatory focus on small groups actually works against these approaches and engenders a kind of “love-bombing” approach for some very small and at risk groups of students.
Sing a simple melody
In other releases, we are more likely to see the ABCs as quintiles. We need to be aware of the impact of student personal and domicile characteristics in the modelling used to generate these in order to put these in context.
So a provider that primarily recruits locally is likely to be in a lower ABCs quintile for both access and continuation, and the nature of the area a provider is situated in will have a wider impact via the impact of measures of deprivation and participation.
Bonus chart
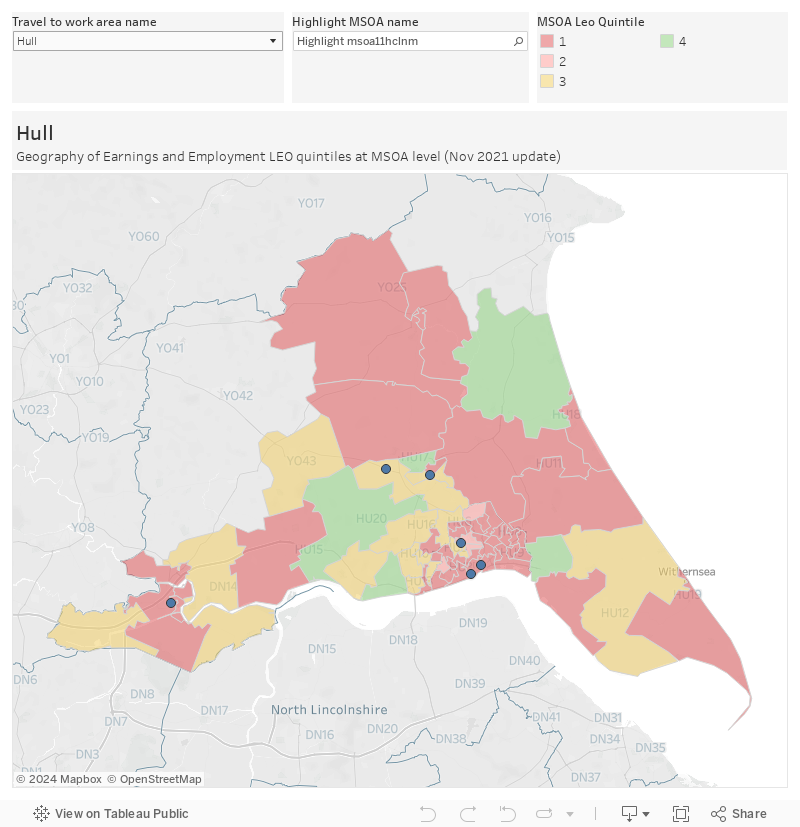
The back end of last year brought a rethink of the Geography of Earnings and Employment data release – this data will also end up used in regulatory analysis. After my many complaints, we now get LEO quintiles (based on the proportion of graduates aged 25-29 in the LEO data set resident in an area with earnings above the national average or in further study) at MSOA resolution rather than just “travel to work areas”.











Wow, a very interesting article.