


HEFCE gave us an early Christmas present last week in its eagerly-awaited consultation on the next REF. Reactions have been positive: it’s a thoughtful document, which avoids binary yes/no choices, asking instead for comments on how best to implement the changes proposed by the Stern Review.
And HEFCE genuinely does want our feedback. As David Sweeney wrote last week on Wonkhe, “Only by harnessing the collective wisdom of the community can we best implement the Stern principles.”
Over and above the forty-four specific questions in the consultation hangs a more fundamental dilemma: how serious are we as a community about overhauling the REF? To borrow from the Brexit lexicon, will we see “hard Stern”: the full, interlocking package of measures recommended by Lord Stern? There is little doubt that these will reduce burden and resolve some weaknesses in the last assessment cycle, but potentially at the cost of adding new complications to the mix. Or will the sector push back, and highlight a range of technical difficulties, ambiguities and unanticipated effects as the basis for “soft Stern”: a 2021 exercise that is closer in its design to REF2014?
In recent days, I’ve spoken to around twenty REF veterans from a spread of universities, mission groups and funding bodies to get their sense of the sharpest faultlines in the consultation, and how they are likely to respond before the deadline closes on 17 March.
I’m going to cluster their comments into three groups: the comfortably consensual; the technically tricky; and the awkwardly absent. Where relevant, I’ve flagged the numbered questions from the consultation in brackets. And I’ll close with a few of my own thoughts on where things are likely to go next.
The comfortably consensual
Everyone I spoke to felt HEFCE had done a good job in taking Stern’s framework and exploring openly how it could best be operationalised. When the Stern Review was first set up, the mood music accompanying it hinted at a wholesale redesign of the exercise, possibly on a metrics-only basis. But when the review emerged in July 2016, it sat comfortably in the 30-year series of evolutionary tweaks that have taken us from the Research Selectivity Exercise in 1986 to the REF today:
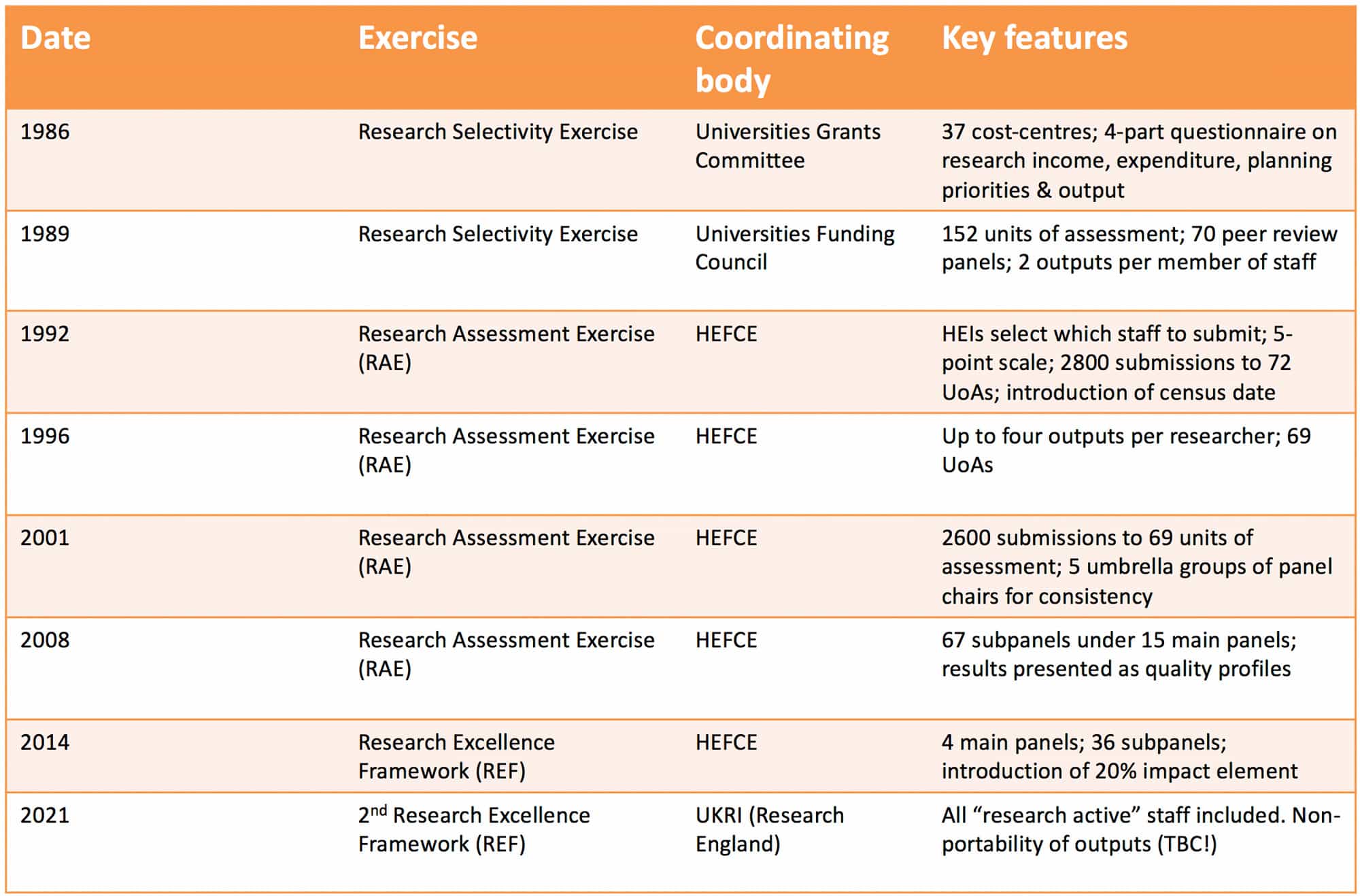
The promise of radicalism in Stern flowed not from any one proposal, but from the compound and cumulative effects of several modest changes at once. Stern himself stressed that his recommendations “should be taken as a complementary package where the logic of one depends on and is strengthened by the others”.
This is the spirit in which the HEFCE consultation is drafted, and there are lots of sensible elements of Stern’s package that the consultation shows can be carried forward without much difficulty. These include proposals around unit structure (2); expert panels (3, 4, 5, 6); ORCID identifiers (11); collaboration (15); metrics (18); adopting a broader approach to impact (19-23); the impact template (25); the case study template (27, 28); underpinning research (29-31); the environment section (34, 35); and open access (36, 37).
There are positive noises in support of interdisciplinarity (16), and although some of those I spoke to argued that more specific measures might be needed here, there was a uniformly warm reception for the new advisory panel on interdisciplinarity that HEFCE announced last week. This will be chaired by Dame Athene Donald, Master of Churchill College, Cambridge, who yesterday gave a preview of what she hopes it will achieve on her blog.
The technically tricky
Stern’s overarching aims – to reduce burden, limit gaming and shift the focus of assessment away from individuals and towards the institutional level – continue to enjoy widespread support As several commentators said when the review was published, Stern’s framework has the potential to create a more diverse research culture, in which universities are incentivised to make more patient and longer-term investments in people.
That’s the theory. The difficulty, as the consultation gently teases out, arises from putting several changes into practice at once – particularly the envisaged trifecta of including all research active staff; decoupling outputs from individuals; and ensuring non-portability of outputs between jobs. Some of the barriers are technical; others are cultural or managerial. But the result is the same: as the proposals are tightly interlinked, once you start pulling at one or two threads, it’s not long before the knot of implementation starts to unravel…
As always with REF, one has to be conscious of the gap that can develop between design principles and operational realities. Stern revealed himself to be acutely sensitive to the ways in which REF2014 generated many positives, but also some negatives, including excess burden; narrow measures of quality and impact; rent-seeking behaviour; and institutional gaming. When it comes to his own reforms, Stern seems optimistic that the same dynamics won’t apply.
Those I spoke to were less sure. One asked whether implementing Stern in full “will produce a different set of issues which – because nobody knows how universities will manage them – may turn out to be worse than last time… My reading of the consultation is that HEFCE suspects this to be the case but is not able to say so.” Another pointed to “the huge tension between Stern’s focus on shifting things to the institutional level, and the persistent desire of HEIs to use REF for individual performance management.”
These tensions are already visible in initial skirmishes over staff selection, numbers of outputs and portability. There are five main issues here:
First, staff selection. The proposal to use HESA cost centres to map research-active staff to REF units of assessment (UoAs) is regarded by many as problematic (7, 8). If it worked, it would make determining who is in a REF submission straightforward. But the reality is that the HESA cost centre data is error-riddled and incomplete. And as it hasn’t been used for research purposes in the past, the codes don’t map straightforwardly onto UoAs.
To share an example from my own university, the entire computer science department at Sheffield is coded to the “electrical, electronic and computer engineering” cost centre (code 119), rather than “IT, systems sciences and computer software engineering” (code 121). So if 119 were used as the basis for REF allocation, the entire department would end up being assessed by the wrong panel! I’m sure we’re not alone in this, but even where departments lie formally under the right code, individuals within them may not.
Workarounds to the HESA data issues could include: HEIs selecting where to put people (although this could unleash more gaming); using the HESA codes but allowing a “flexible buffer” of x% of staff who could be moved around to improve accuracy; or HEIs declaring their own structures (faculties/departments/centres etc.) and proposing relevant UoAs (not using HESA codes at all). This approach has many advantages but would need to be agreed soon, to get a sense of the size of each UoA.
Second, HESA’s definition of “research active” includes research assistants and postdocs working on projects led by others. The numbers in this camp are particularly large in the life sciences, so there would need to be some further analysis of what “research active” means on a case-by-case, or group-by-group basis. This would deliver a more accurate picture but would move us back towards something close to staff selection and identification of “special circumstance” that was so time-consuming in REF2014.
Third, difficult choices in the number of outputs required (9). Stern recommended a decoupling of outputs from individuals, a sliding scale of 0-6 outputs per research-active FTE, and an average of two outputs per FTE overall (to limit the burden on REF panels). This reduces burden in one respect but may increase it in another. Selecting the best outputs from everything a UoA has produced requires more fine-grained judgment than choosing the best four from each person. And the process may be just as contentious as choosing staff. How many researchers will be upset if none of their outputs are chosen, as they would have been if they themselves had not been included in earlier exercises?
As David Sweeney noted last week, this model would mean the body of work submitted “could potentially represent the work of only a third of all staff…Is that a more rounded assessment?” To make the point less politely, after REF2014 there was intense criticism of the way some HEIs excluded researchers in order to bump up their average output scores. Cardiff was a well-known case (though far from alone), opting for a highly selective submission to claim a “meteoric rise” to 5th best university in the REF. Under Stern’s model, Cardiff (allowing some staff to submit 0 and others 6) could submit a similar set of outputs as last time while including everyone.
This would also mean fewer outputs per FTE from the best places which submitted a high percentage of staff in 2014 and more from those with large numbers of staff who weren’t submitted in 2014. And nearly all the outputs from the top 10-12 universities are likely to be 4* (assuming these can be accurately identified), which will make differentiation at the top of the system – and eventual allocation of resource on this basis – far more difficult.
Alternatively, if you insist on everyone submitting at least one output, you again head back towards a version of REF2014’s staff selection. A floor of one would also increase the likelihood of some staff being moved onto teaching-only contracts, a trend which already seems to be picking up across the sector, even while the rules for REF2021 remain fluid.
Some argue that a scale from 0-4, rather than 0-6 would be preferable, and give a more accurate picture. But this would mean an average of 3 outputs per FTE, so a burdensome increase of ~100,000 outputs in the total volume to be assessed. Sampling would be the best way through this issue, but Stern rather surprisingly ruled against this (despite the British Academy, Academy of Social Sciences and others being in favour). So it may be that this comes back into play as an option….
A fourth set of issues arises from the non-portability of outputs (10). As was widely discussed when Stern published, this creates particular uncertainties for early-career researchers who increasingly move from one fixed-term contract to another in order to even have a shot at a permanent job. But there are other technical issues. For journal articles, do you take point of submission or acceptance as the cut-off date? Acceptance has the advantage of consistency with the REF’s open access requirements but can come months or even years after the actual research was done in some social science and humanities journals. And researchers could still hoard papers under revision and use these to secure a job elsewhere (“I’ve got three 4* articles ready to go if you hire me next month!”)
For books and monographs, the cut-off date is even more debatable – as the research, writing and publishing process can span several years. There is little choice but to rely here on self-declaration, but it will be very hard to audit this. And on what basis should multiple HEIs be allowed to submit the same output? This happens already with co-authored outputs but could potentially apply now to the same author if a major output spans two jobs. A further question is what to do about overseas hires? This isn’t mentioned in the consultation – and one assumes that the same rule would apply; otherwise it could make it far more attractive to hire from overseas.
It will be interesting to see if there’s a pre-2021 spike in the volume of disputes between individuals and HEIs over where particular work was done. In the last REF, even without non-portability, there were around fifty disputes over institutional affiliation, five of which HEFCE had to end up adjudicating.
A few suggest we should, therefore, drop the non-portability clause – despite potential positive effects, and being in many ways fairer to institutions. As with other technical issues in REF, this is an example of how the perfect can easily become the enemy of good. More granular accuracy and a precise allocation of credit sits in tension with a fairer system that may reduce (some) negative incentives and support more patient investment.
Finally, there are concerns over the practicality of institutional impact case studies (38). While the broad approach to impact in the consultation is welcomed, those I spoke to expressed concern over how the new institutional cases would work – especially now it is being proposed that they should account for 5 per cent of the total weighting of the exercise.
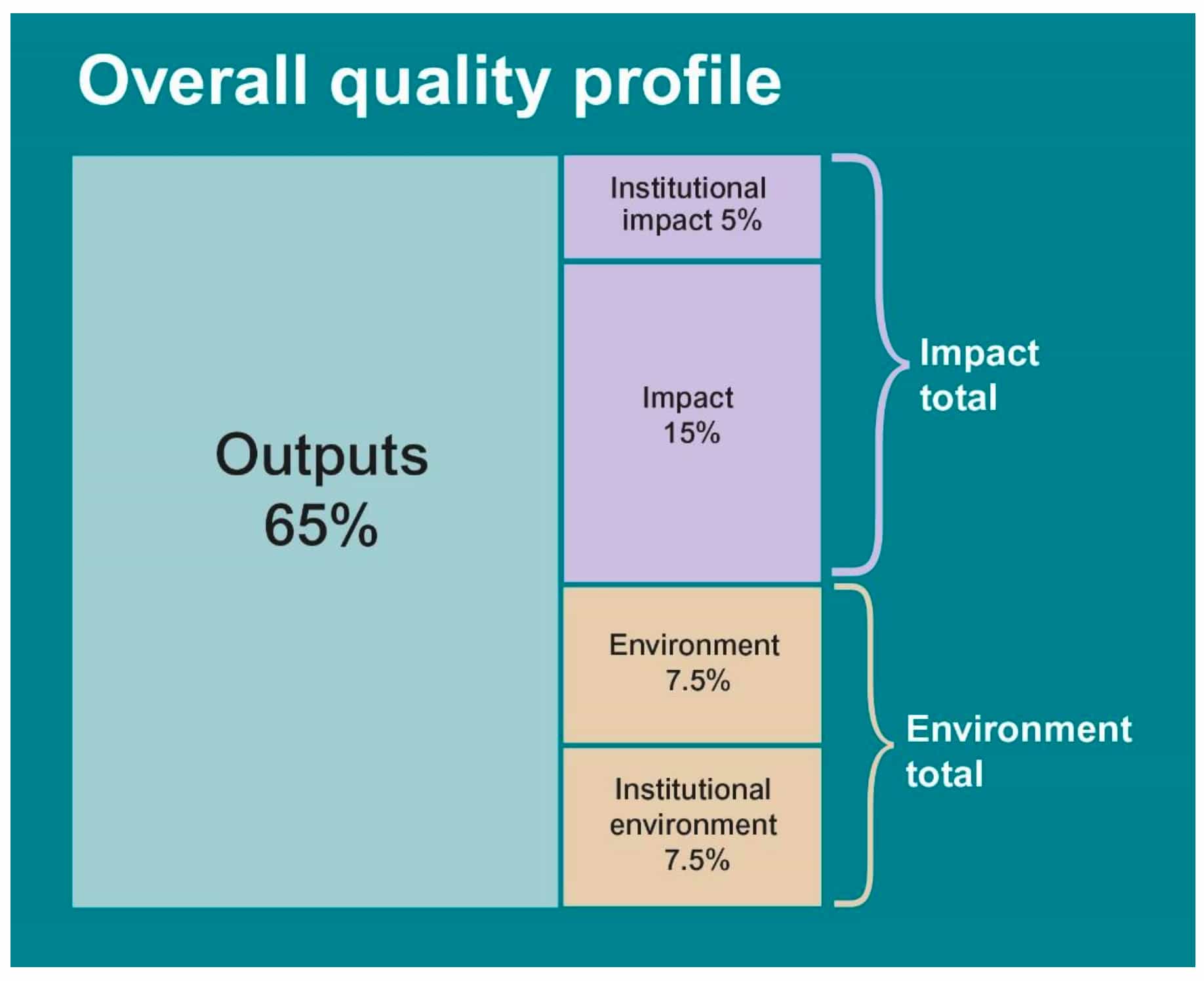
HEFCE accepts that the detail here is still too sparse. But they argue that if the institutional cases were fully optional, no HEIs would include any, as they are clearly more complicated than normal cases. So the five per cent is a way of trying to deliver Stern’s objectives in this area.
Those I spoke to expressed reservations over whether impacts genuinely take place at the institutional level? There is a risk that these become an artificial PR construct of the REF – not a genuine reflection of how and where impact occurs. There are also questions over what smaller or mono-discipline HEIs are supposed to do? And there are different challenges for large research-intensives. One expert told me he couldn’t imagine what a University of Oxford-wide case would look like: “there are simply no levers at that level; no structures to enable this to happen.” Another told me “the more we look at this, the messier it gets. Stern’s suggestion that we broaden the definitions of impact is sensible, but these cases bring no obvious benefits and introduce lots of extra complexity. They are a solution in search of a problem that doesn’t exist.” So as the responses start to flow, it seems that this is one idea that may get well and truly kicked into touch.
The awkwardly absent
On a closer read of the consultation, two issues stand out as surprising omissions. The first is the absence of any discussion of the potential to introduce a new 5* rating, as advocated recently by Simon Kerridge on Wonkhe which could help to overcome the effects of bunching and the difficulties of discerning quality at the top end. This could also make HEFCE’s task of allocating resources easier.
As some have spotted, the option of a 5* rating was included in an earlier draft of the consultation (copies of which were circulating surreptitiously a few in dark corners of the HE community a few weeks ago). But this ended up on the cutting room floor – rumours suggest at the direct intervention of Jo Johnson and senior BEIS officials, who were worried about the effects of “grade inflation” on perceptions of quality across the system.
A second surprise was reappearance at the start of the document of the 2014 threefold definition of the purposes of REF. As I’ve written about before many of the tensions in sector debates over the costs and benefits of the REF, stem from people arguing at cross purposes, or framing the exercise in an overly narrow way. I’ve suggested that there are in fact five purposes; Stern went one better and proposed six. So it’s a shame to see the status quo reasserted here without the open discussion of pros and cons that we see elsewhere in the document.
Next steps
Following the autumn statement, with its announcement of an extra £4.7 billion for research and innovation, the stakes for the next REF are higher than ever. A proportion of this new money – I’d imagine around £350m per year by 2020 – has to go towards QR funding to deliver the commitment to a “balanced funding system” in part 3 of the HE and Research Bill.
The sector now has until 17th March 2017 to respond to the questions in the consultation, and the new rules are set to be finalised by the middle of 2017. Whether we end up with soft Stern, hard Stern or somewhere in between will depend on how much support there is to maintain the integrity of his connected package, even if that comes at the expense of some loss of accuracy and effects that will play out unevenly across the sector. After thirty years, and as we approach its eighth cycle, the REF has become a highly sophisticated model of what sociologist Peter Dahler-Larsen calls an “evaluation machine”.
Responsibility for that machine will move in April 2018 to a new home – Research England – and the assumption is that David Sweeney will remain at the wheel. He is seen by many as a “dead cert” to be Research England’s first executive chair, and undoubtedly has the track record to take it on. However, this choice may ultimately lie with the first Chief Executive of UKRI, whose identity is expected to be announced any day now. Apologies to anyone who placed a bet on the basis of my last prediction, as it seems Borys, Cambridge’s VC, has withdrawn his name (apparently for family reasons). But the gossip mill suggests that there’s a new high-profile American candidate in the frame – France Córdova, current director of the US National Science Foundation, who was spotted in London recently and may welcome a trans-Atlantic escape chute from managing research policy under President Trump. What she will make of the REF remains to be seen….











Neither Hard nor Soft. Surely it’s now a Red, White and Blue Stern?
It isn’t clear to me that there is a proposal to “broaden the definitions of impact”. I read it as suggesting that the definition stays much the same, but that they will try to make it clearer that REF is looking for impacts beyond the simplistic bean counting of economic returns.
When editing some impact statements in REF2014 from unnamed universities, I had to work hard to get them to include impacts on policy, the public and wider society in general. There’s more to impact that additions to corporate bottom lines.
At least they have abandoned the notion, much loved by David Sainsbury, that you can judge impact by counting spinout companies.
We were originally (in the 1980s) told research assessment was to make sure all university teaching staff were research active. It has actually achieved a divorce between research activity and teaching. The only way back is for ALL teaching staff- full time, part time, zero hours contracts – to be included in assessment and for universities to be marked down if teaching staff have not been given time to produce work of the appropriate quality.
We were also told that research assessment was to broaden the research base. Again, it has achieved the opposite. Thoughts on that, anyone?
Great piece, James – thank you.
Occurs to me that departmental coding (and grouping of departments within a single code) will be a huge issue for TEF as well. I think a lot more people are going to get more interested in HECoS
I enjoyed reading this carefully argued piece. I agree that the subject coding (and unclear mapping of UoAs to subject coding) is potentially a large issue, maybe particularly for Panel B, but potentially for all panels. It occurs to me that attempting to align researchers with subject codes might mitigate against interdisciplinary research – or at least a coherent UoA environment statement. But perhaps that will be an important purpose of the institutional environment statement?